This project examines ProteinTuneRL from a reinforcement learning perspective and uses it as a practical framework for thinking about antibody sequence design as constrained optimisation in sequence space. The focus is not only on the biological motivation, but also on how different online RL algorithms behave when the action space is made of amino-acid tokens rather than actions in a simulated environment.
Introduction
Proteins are the functional units of biological systems. They perform structural, signalling, and regulatory roles, and their behaviour is determined by how they fold in three dimensions. Proteins are built from amino acids, small organic molecules that join into long chains, but function is not defined by sequence alone.
After a protein is formed, the amino-acid chain folds into a 3D structure due to physical interactions such as electrostatics and hydrophobic effects. This leads to a central principle of protein science:
sequence → structure → function
Recent advances such as AlphaFold have shown that machine learning can predict protein structures at scale. But accurate structure prediction alone does not solve protein design. Real biological function also depends on stability, binding behaviour, and evolutionary constraints.
A clear example of this complexity is the immune system. Antibodies are proteins that bind to foreign molecules such as viruses or bacteria. Their effectiveness depends on how well they bind their targets, which is highly sensitive to small sequence changes. Designing antibodies is therefore a difficult optimisation problem.
From Antibody Structure to Sequence Modelling
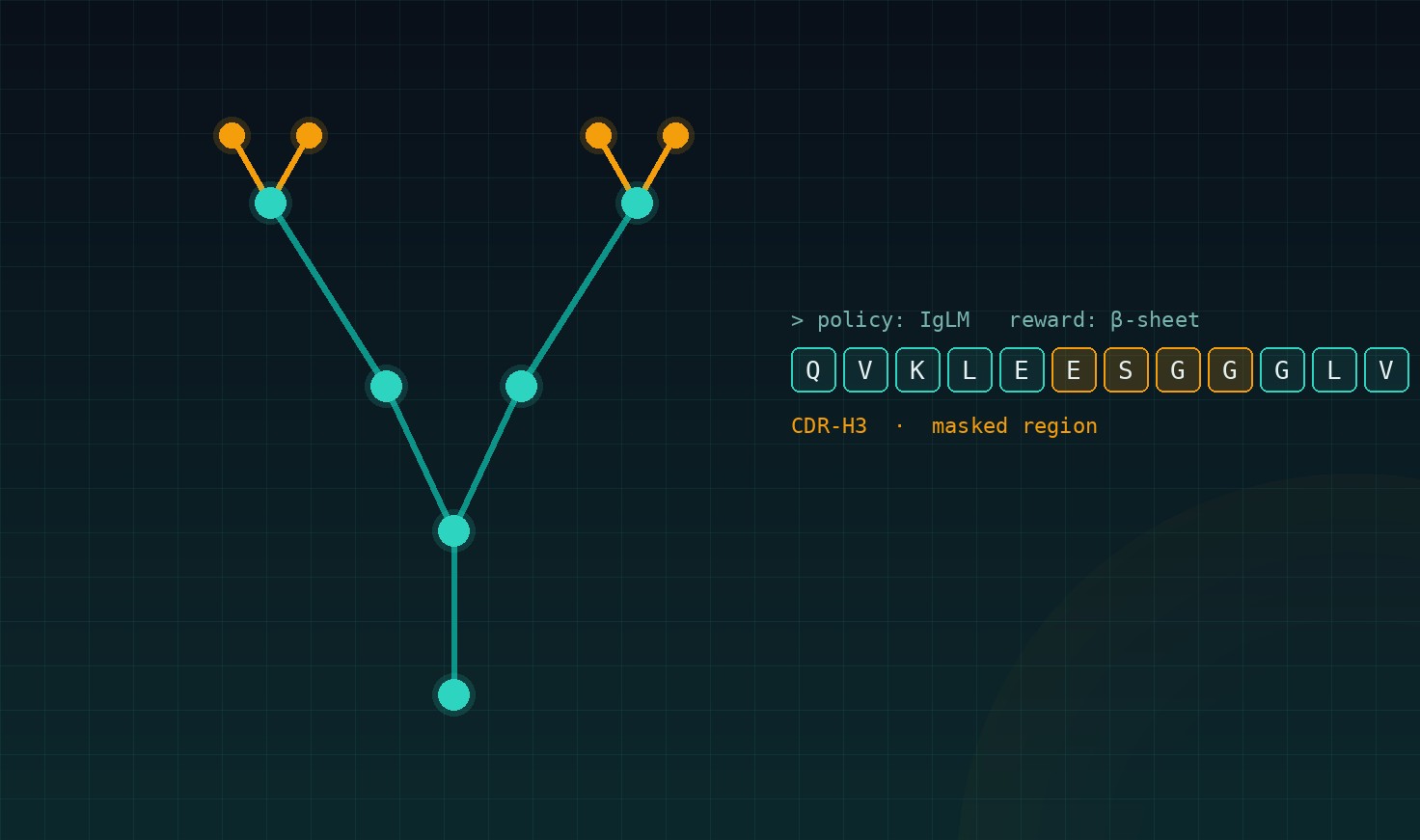
Antibodies have a characteristic Y-shape. The tips of the Y are responsible for binding to targets. Binding occurs through short, flexible regions called Complementarity Determining Regions (CDRs). Among these, CDR-H3 is often the most variable and one of the most influential for binding behaviour.
Although proteins are sequences, their function depends on folding. Computing full 3D folding for every candidate sequence is too expensive to use inside an optimisation loop, so ProteinTuneRL relies on proxy objectives: cheap-to-compute signals that correlate with structural behaviour.
One such proxy is beta-sheet propensity, which estimates whether a sequence is likely to form beta-sheet-like structures. It is not a guarantee of correct folding, but it provides a practical signal that can be optimised efficiently.
From a computational viewpoint, proteins can be treated as strings over a fixed alphabet of about 20 amino acids, each represented by a single letter. This allows protein sequences to be modelled using language models. ProteinTuneRL is centred around IgLM, an antibody language model designed for infilling: masking a region such as a CDR loop and generating plausible replacements conditioned on the surrounding context.
Framing Antibody Design as Reinforcement Learning
With a target region to optimise and a cheap proxy objective to score completed sequences, antibody design can be framed as a sequential decision-making problem over discrete symbols.
The mapping to standard RL components is:
- State: the antibody sequence with a masked region, together with surrounding sequence context.
- Action: selecting amino acids to fill each position of the masked CDR loop.
- Policy: the protein language model, which defines a conditional probability distribution over amino acids.
- Reward: a scalar proxy score such as beta-sheet propensity.
- Environment: a deterministic evaluator that scores the completed sequence.
This framing highlights why supervised learning alone is insufficient. A language model trained only on existing antibody data learns what is typical, but not what is optimal for a specific design objective. Reinforcement learning allows the model to move beyond imitation and explicitly optimise toward a goal while remaining constrained by the learned biological prior.
ProteinTuneRL primarily uses Proximal Policy Optimization (PPO) together with an explicit KL-divergence regularisation term that penalises deviation from the original pretrained IgLM. Conceptually, that creates a controlled trade-off between:
- exploration toward higher-reward sequences
- retention of biological realism learned from data
This is the central idea of the framework: reinforcement learning is useful here not as a black-box optimiser, but as a principled extension of probabilistic sequence modelling under constraints.
What the Framework Does in Practice
At a high level, ProteinTuneRL is a toolkit that lets reinforcement learning operate on protein sequences without requiring full physics-based simulation inside the training loop.
The workflow is intentionally simple:
- Start with a real antibody sequence and keep most of it fixed.
- Mask a small region, usually a CDR loop.
- Use IgLM to fill in the missing amino acids.
- Score the generated sequence using a proxy objective.
- Apply reinforcement learning so future generations move toward higher-scoring sequences while remaining close to the pretrained biological prior.
From an RL perspective:
- the policy is the language model
- the action is choosing amino acids for the masked region
- the reward is a proxy for structural or functional quality
- the environment is the fixed antibody context plus the scoring function
This design makes ProteinTuneRL practical for experimentation: it is flexible, computationally tractable, and well suited for analysing reinforcement learning behaviour in a real biological sequence-design setting.
Project Extensions Implemented
This project builds directly on the ProteinTuneRL codebase. The framework supports both online reinforcement learning, where new sequences are sampled and optimised on the fly, and offline alignment methods, where the model is adjusted using fixed datasets or preference-style supervision.
From a software perspective, the system is driven by a single entry point that selects trainers, optimisers, and evaluators from configuration files. That modular structure makes it a good environment for comparing RL algorithms while keeping the biological setup largely fixed.
A2C + GAE Online RL
The main implementation extension in this project is a new online Advantage Actor-Critic (A2C) algorithm with Generalized Advantage Estimation (GAE).
The motivation for adding it was to explore an alternative to PPO that is:
- lighter-weight than PPO
- more stable than pure REINFORCE
- more directly aligned with classical actor-critic theory
In this formulation, the language model acts as the actor, while an additional value head estimates expected return for each generated token in the infilled sequence. Because antibody infilling produces variable-length sequences, the design requires a token-level value function rather than a single scalar value estimate.
ProteinTuneRL computes a single reward for the completed sequence. That terminal reward is assigned to the final generated token, and GAE propagates the signal backward across the infill positions so that earlier token choices receive meaningful learning signal.
REINFORCE as a Baseline
ProteinTuneRL already includes a REINFORCE implementation. In this project, it is used as an explicit baseline algorithm for comparison against PPO and A2C. Entropy regularisation is added through configuration to reduce policy collapse.
This baseline is useful because it makes the optimisation trade-offs easier to interpret: variance, stability, and convergence behaviour become visible in a relatively raw form.
Explicit KL-Regularised Optimisation
A central concern in protein design is maintaining proximity to the pretrained biological prior. ProteinTuneRL already supports an explicit KL-divergence penalty between the updated policy and the original IgLM, and this mechanism is used directly in the experiments.
This KL regularisation provides a clean and interpretable control knob:
- increasing the KL weight constrains exploration and preserves biological realism
- decreasing it allows more aggressive optimisation of the proxy reward
Importantly, this regularisation is applied at the reward level, making it compatible with PPO, A2C, and REINFORCE.
Results and Training Behaviour
This part of the project is less about chasing state-of-the-art results and more about understanding how online RL algorithms behave in a protein-sequence setting.
Throughout training, two quantities are especially useful:
- Reward: the optimisation objective used during training. When KL regularisation is enabled, the reported reward already includes a negative KL term.
- KL divergence: a measure of how far the fine-tuned policy drifts from the pretrained IgLM distribution.
The key practical point is that protein design is not a pure reward-maximisation problem. Drifting too far from the pretrained distribution quickly leads to unrealistic sequences, so constrained optimisation matters as much as raw score improvement.
PPO
Result plots and screenshots will be added here.
PPO behaves in the expected conservative way:
- reward rises early and then flattens into a stable plateau
- KL increases initially and then stabilises rather than exploding
- training remains smooth, with no major oscillations or runaway dynamics
This is effectively PPO doing what it is designed to do: trading speed for stability in a high-dimensional discrete action space.
A2C + GAE
Result plots and screenshots will be added here.
A2C with GAE learns faster, but with sharper edges:
- reward climbs quickly and can match or exceed PPO early on
- KL grows more aggressively
- later in training, reward may dip as policy drift increases
This behaviour is consistent with actor-critic theory. GAE improves credit assignment, but without PPO-style clipping the policy has more freedom to drift.
REINFORCE
Result plots and screenshots will be added here.
REINFORCE behaves like a textbook high-variance policy-gradient baseline:
- reward improves, but noisily
- KL tends to grow steadily with limited self-correction
- convergence is slower and less reliable
This baseline confirms that the optimisation signal is real, while also showing why variance reduction and trust-region-style constraints matter in sequence design problems.
Explicit KL-Regularised REINFORCE
Result plots and screenshots will be added here.
Adding an explicit KL penalty changes REINFORCE substantially:
- KL is actively controlled and may even decrease over time
- reward plateaus earlier and often lower
- training becomes materially more stable
This makes the underlying trade-off visible: optimisation is no longer simply about chasing reward, but about balancing reward against biological plausibility.
Convergence and Step Budgets
Across the online algorithms, most of the meaningful learning appears to happen within roughly 1,000 to 2,000 steps. After that point:
- reward gains saturate
- KL dynamics increasingly dominate behaviour
- further training mostly trades realism for marginal proxy improvement
For this task and this proxy setup, early optimisation seems to capture most of the useful signal.
Takeaway
The core lesson from this project is simple:
Reinforcement learning for protein design is not about maximising reward. It is about managing drift.
PPO, A2C, and explicit KL regularisation are different ways of navigating the same trade-off: how far to move away from a strong biological prior while still making progress toward a design objective. ProteinTuneRL is compelling not because RL is magical, but because it treats optimisation as constrained exploration in sequence space.